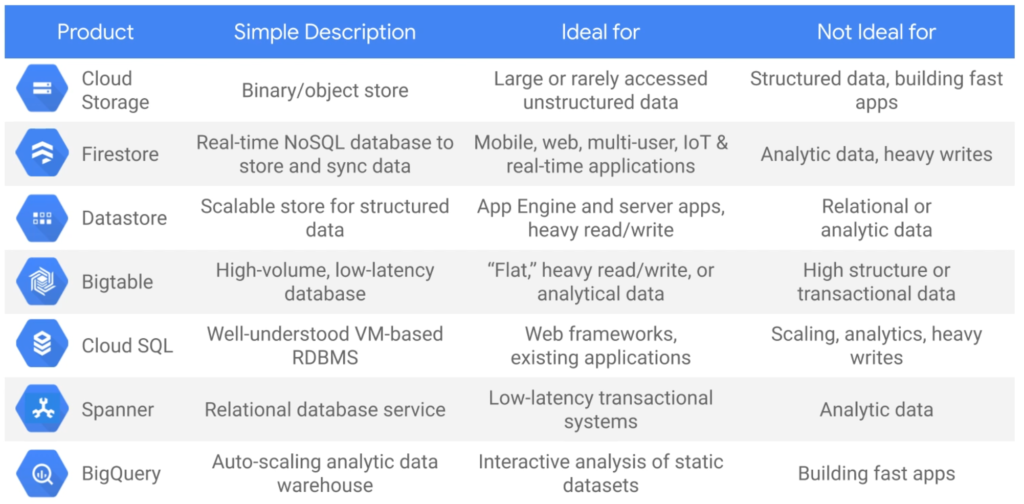
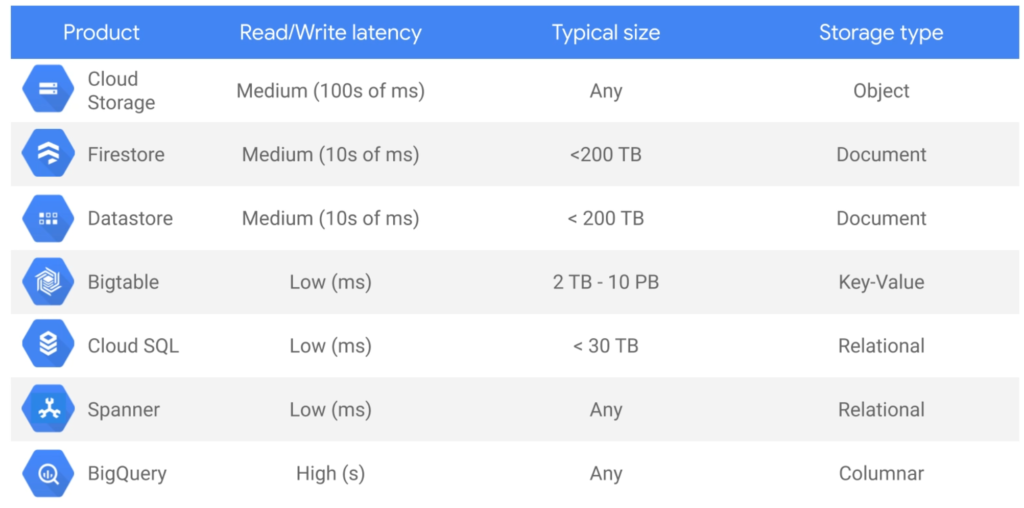
Overview of ways to store data in the Google Cloud
We first have to differentiate between
- Storing binary data (BLOBs)
- Storing data using a database management system (SQL, NoSQL etc.)
Data can be structured, unstructured, transactional or relational.
Different applications demand different types of storage solutions. You might use one or more storage solutions at the same time for one application.
Google cloud services for binary storage
Block storage via Google Persistent Disks
- Google Cloud Persistent Disk
- Is used by all virtual machines in Google Cloud and Google Kubernetes Engine service
- Think of Persistent Disks as mere USB drives which can be attached or detached from virtual machines
- can either be HDD or SSD for higher I/O performance
- ability to choose where they are located (Regional, Zonal, or Local) and what type of availability is needed
- automatic encryption
- flexibility to resize while-in-use
- snapshot capability (use for backup and/or virtual machine image creation)
Network File Storage via Google Filestore
- network file storage is technically block storage that provides a disk storage over the network
- Think of NAS concept
- Enables the development of systems with multiple parallel services that has the ability to read and write files from the same disk storage mounted over the network
- performance is substantially inferior in comparison to the other two storage types
- might lead to issues with concurrency and file permissions
Object Storage via Google Cloud Storage
- usually pictures, video and audio for website content, archival & disaster recovery or direct downloads
- you must use a REST API to get and put any file, so the typical filesystem approach does not work
- stored as an object with metadata: author, date created, permissions and GUID
- all objects are immutable: an object is not edited but a new version is created with every change made. You can then either overwrite the old version (default) or keep versions to maybe restore them later.
- permissions using inheritance from IAM or, if fine-grain permissions is required per object or bucket, use ACLs by defining a scope (user or group) and a corresponding permission (allowed actions).
- can expand indefinitely with each object growing up to the terabyte scale
- different objects are grouped in unique “namespaces” called buckets which hold multiple objects yet, a single object will belong to only one bucket
- low cost (cents per GB) and pay only for what you use
- Highly popular with cloud-native systems in combination serverless functions for its simplicity
- data replication, availability, integrity, capacity planning, etc. is then left to the cloud provider
- concept of storage classes (Standard, Nearline or Coldline)
- Lifecycle Management policies enables you to define business logic rules per bucket without much effort: you can define actions such as automatically transitioning objects between different storage classes, disable versioning, or even delete objects after certain defined periods of time
- No prior provisioning of capacity
- encrypts data on the server side and in transit
Google cloud services for database storage
Cloud Datastore got deprecated in favor of Firestore.
About Author

I am Mathias from Heidelberg, Germany. I am a passionate IT freelancer with 15+ years experience in programming, especially in developing web based applications for companies that range from small startups to the big players out there. I create Bosycom and initiated several software projects.