Streams are collections of data that might not be available all at once and don’t have to fit in memory all at once. For example if you want to serve a file that is 1GB over HTTP you would create a stream instead of reading the file using readFileSync. A readable stream can be piped directly to another writable stream. All Streams are EventEmitters in Node and as such expose certain events that play important roles when handling streams. Generally, you can read data from any readable stream by using myStream.on('data', (data) => ...).
Four types of streams in Node
- Readable (e.g.
fs.createReadStream) - Writable (e.g.
fs.createWriteStream) - Duplex (are readable and writable like
net.Socket) - Transform (are duplex streams that can be transformed as they are written or read such as
zlib.createGzip)
You can connect streams using src.pipe(dst) only if src is a readable stream and dst is a writable stream, not the other way around.

Example of a custom writable stream
Here is a writable stream that writes random strings to a file every second for 5 seconds:
const fs = require('fs');
const crypto = require('crypto');
const writeStream = fs.createWriteStream('streaming.txt');
let interval = 5;
const intervalId = setInterval(() => {
if (interval === 0) {
writeStream.close();
clearInterval(intervalId);
return;
}
const randomData = crypto.randomBytes(10).toString('hex') + '\r\n';
writeStream.write(randomData)
interval -= 1;
}, 1000);
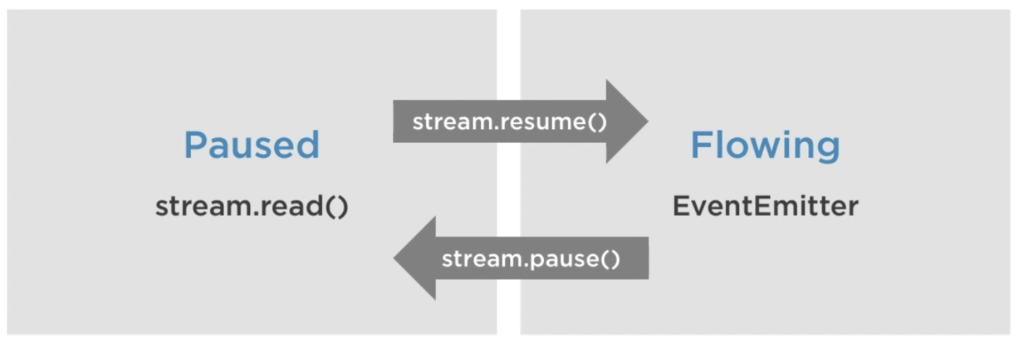
Paused and Flowing streams
Readable streams are either Paused or Flowing. When Paused we have to use stream.read() to obtain the data, when Flowing we have to use the appropriate events instead. In Flowing mode data can actually be lost if they are not consumed. In fact, just adding a ‘data’ event handler switches a readable stream from Paused to Flowing, and removing the ‘data’ event handler switches it back from Flowing to Paused. But usually you should use stream.resume() and stream.pause() to change the mode.
An example of a custom Writable Stream
const {Writable} = require('stream');
const myWritable = new Writable({
write(chunk, encoding, callback) {
// chunk is usually a buffer
// encoding is the buffer encoding
// callback is what we need to call after we are done processing the data chunk
console.log('Processed:', chunk.toString());
callback();
}
});
// to consume our writable stream we have to pipe it to a readable stream, in
// this case stdin
process.stdin.pipe(myWritable);
Now, when we start the program and type in Test and press Enter, we get:
Processed: Test
The whole previous example is very contrived because the same can simply be achieved in one line:
process.stdin.pipe(process.stdout);
An example of a custom Readable Stream
const {Readable} = require('stream');
const rs = new Readable();
rs.push('ABCDEFGHIJKLMNOPQRSTUVWXYZ');
// pushing 'null' signals to the stream that we do not have more data
rs.push(null);
// stdout is a writable stream. We pipe it to our readable stream;
rs.pipe(process.stdout);
The problem here is that we are already pushing all of the data before we pipe the data to stdout. Instead we should push data on demand, when the user asks for it.
In the following example we push a new charcode every 200 ms to a readable stream, starting from A ending with Z.
const {Readable} = require('stream');
const rs = new Readable({
read(size) {
setTimeout(() => {
if (this.currentCharCode > 90) {
// we stop streaming on letter 'Z'
this.push(null);
return;
}
// we can push partial data
this.push(String.fromCharCode(this.currentCharCode++));
}, 200);
}
});
rs.currentCharCode = 65; // that's the letter 'A'
rs.pipe(process.stdout);
process.on('exit', () => {
console.log(`\n\ncurrentCharCode is ${rs.currentCharCode}`);
})
// if we invoke this script with 'node readable.js | head -c3' then head
// causes an error. Therefore we have to add this following line:
process.stdout.on('error', process.exit);
We can force our stream to stop on the letter ‘D’ to prove that we only stream data on demand:
node readable.js | head -c3
Duplex stream
For Duplex streams you have to implement both, read and write methods, just as in the examples before.
const {Duplex} = require('stream');
const duplex = new Duplex({
read(size) {
// ...
},
write() {
// ...
}
});
process.stdin.pipe(duplex).pipe(process.stdout);
Transform stream
const {Transform} = require('stream');
const upperCaseTr = new Transform({
transform(chunk, encoding, callback) {
this.push(chunk.toString().toUpperCase());
callback();
}
});
process.stdin.pipe(upperCaseTr).pipe(process.stdout);
In the following example we compress a file that we pass in as command line argument:
const fs = require('fs');
const zlib = require('zlib');
const file = process.argv[2];
fs.createReadStream(file)
.pipe(zlib.createGzip())
// use a dot to indicate progress
.on('data', () => process.stdout.write('.'))
.pipe(fs.createWriteStream(file + '.gz'))
.on('finish', () => console.log('Done zipping file'));
We can further enhance this example: We write a stream that will show the progress, instead of using the ‘data’ event above. Also we encrypt our data:
// zip.js
const fs = require('fs');
const zlib = require('zlib');
const {Transform} = require('stream');
const crypto = require('crypto');
const file = process.argv[2];
const progress = new Transform({
transform(chunk, encoding, callback) {
process.stdout.write('.');
// chunk argument pushes the data
callback(null, chunk);
}
})
fs.createReadStream(file)
.pipe(zlib.createGzip())
.pipe(crypto.createCipheriv('aes192', 'mySecret', 'myIv'))
.pipe(progress)
.pipe(fs.createWriteStream(file + '.enc'))
.on('finish', () => console.log('Done zipping file'));
node zip.js myFile.txt
We can write another script, that will decrypt and unzip a file:
// unzip.js
const fs = require('fs');
const zlib = require('zlib');
const {Transform} = require('stream');
const crypto = require('crypto');
const file = process.argv[2];
const progress = new Transform({
transform(chunk, encoding, callback) {
process.stdout.write('.');
// chunk argument pushes the data
callback(null, chunk);
}
})
fs.createReadStream(file)
.pipe(crypto.createDecipheriv('aes192', 'mySecret', 'myIv'))
.pipe(zlib.createGunzip())
.pipe(progress)
.pipe(fs.createWriteStream(file.slice(0, -3)))
.on('finish', () => console.log('Done zipping file'));
node unzip.js test.file.enc
Redirecting console output to files
const fs = require('fs');
const out = fs.createWriteStream('./out.log');
const err = fs.createWriteStream('./err.log');
const fileLog = new console.Console(out, err);
let intervals = 5;
const disable = setInterval(() => {
console.log(`Logging to file. Interval is ${intervals}`);
fileLog.log(new Date());
if (intervals === 0) {
fileLog.error(new Error('Oops'));
clearInterval(disable);
}
intervals -= 1;
}, 2000);
About Author

I am Mathias from Heidelberg, Germany. I am a passionate IT freelancer with 15+ years experience in programming, especially in developing web based applications for companies that range from small startups to the big players out there. I create Bosycom and initiated several software projects.